As part of its Google Cloud, Google offers the Google Translation API with a usage-based cost structure. In addition, there is an undocumented API that can be used without a key, but which denies service after only a few requests. When using the website translation function of Google Chrome, it is noticeable that pages can be translated here in very good quality without any noticeable limitation.
apparently, the advanced nmt model is already used here. but what API does Google Chrome use internally to translate the content and can this API be accessed directly - even on the server side? to analyze network traffic, tools like Wireshark or Telerik Fiddler are recommended, which can also analyze encrypted traffic. but Chrome even delivers the requests it sends during page translation free of charge: they can be easily viewed via the Chrome DevTools:
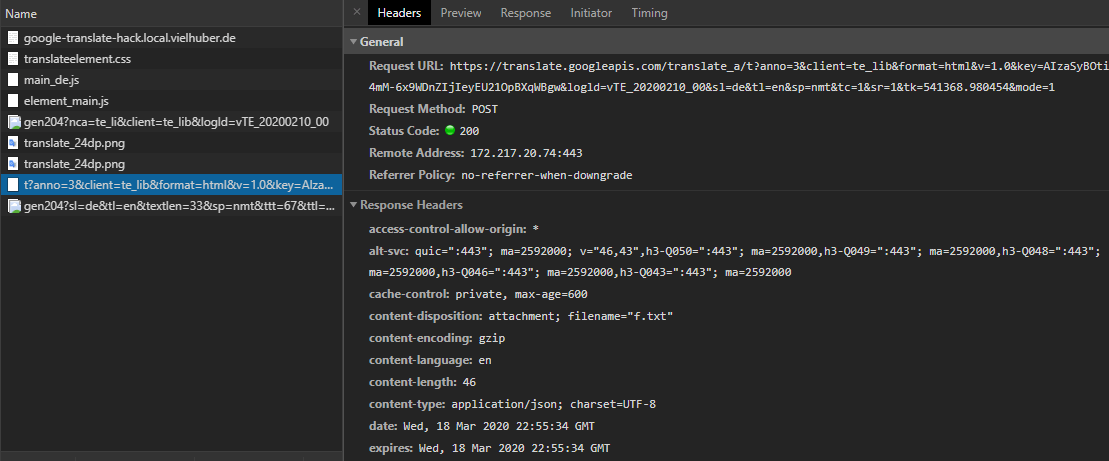
If you do a translation, then catch the decisive POST request https://translate.googleapis.com via "Copy > Copy as cURL (bash)" and execute it in a tool like Postman, for example, you can resend the request without any problems:
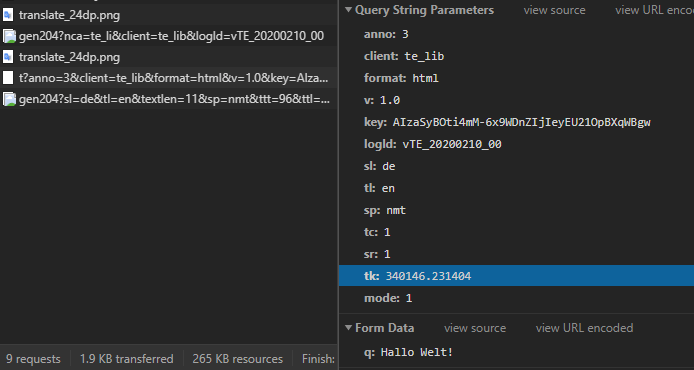
The meaning of the URL parameters are also largely obvious:
| Key | Example Value | Meaning |
| anno | 3 | Annotation mode (affects the return format) |
| client | te_lib | Client information (varies, via the web interface of Google-Translate the value is "webapp"; affects the return format and the rate limiting) |
| format | html | String format (important for translating HTML tags) |
| v | 1.0 | Google Translate version number |
| key | AIzaSyBOti4mM-6x9WDnZIjIeyEU21OpBXqWBgw | API key (see below) |
| logld | vTE_20200210_00 | Protocol version |
| sl | en | Source language |
| tl | en | Target language |
| sp | nmt | ML model |
| tc | 1 | unknown |
| sr | 1 | unknown |
| tk | 709408.812158 | Token (see below) |
| fashion | 1 | unknown |
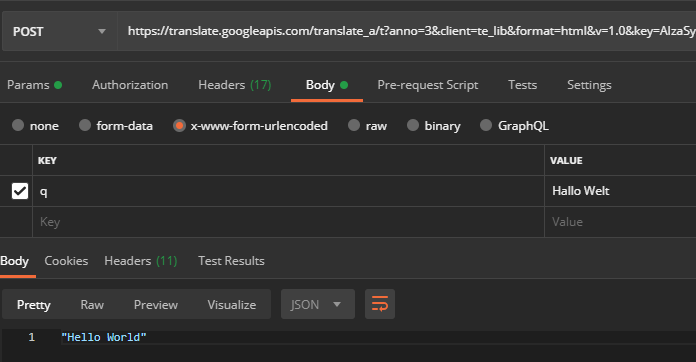
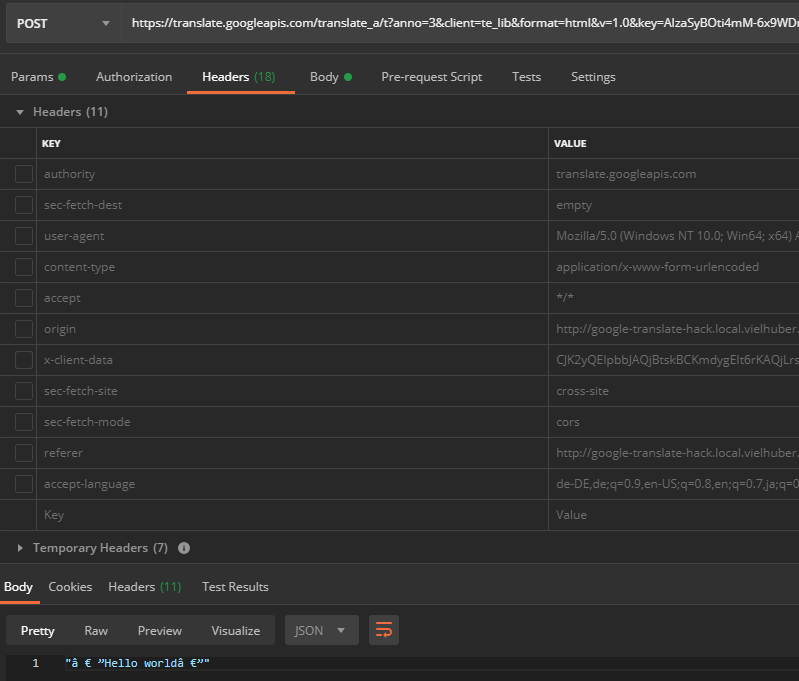
Some request headers are also set - but these can mostly be ignored. After manually deselecting all headers, including those from the user agent , an encoding problem is discovered when entering special characters (here when translating " Hello World "):
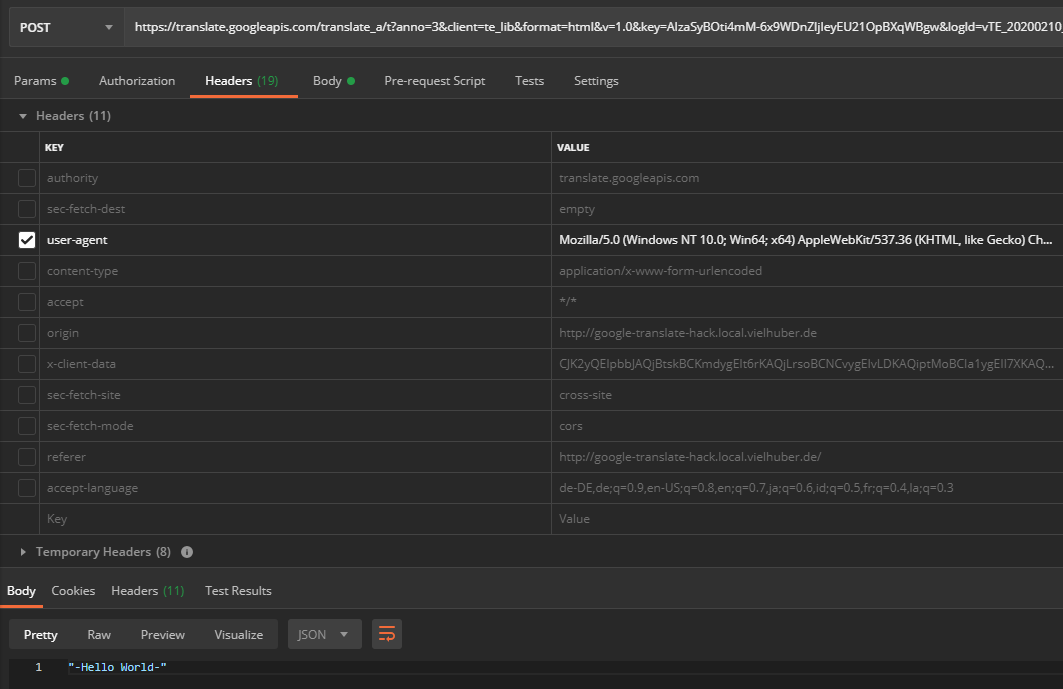
If you reactivate the user agent (which generally doesn't do any harm), the API delivers UTF-8 encoded characters:
Now that we have all the information we need to use this API outside of Google Chrome, if we change the string to be translated (data field q of the POST request) from, for example, "Hello World" to "Hello World", we get an error message:
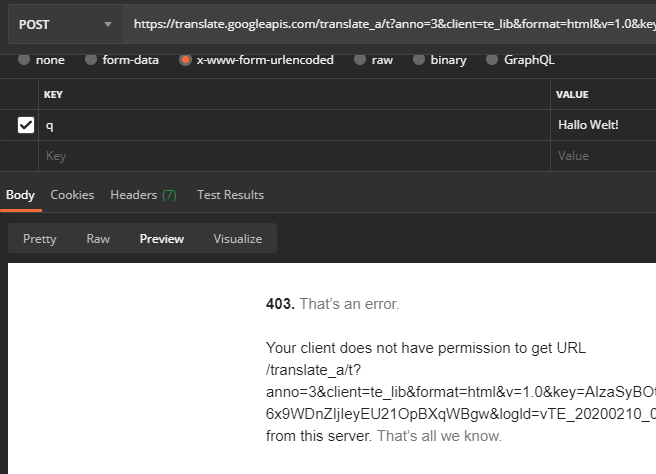
We now retranslate this modified one within Google Chrome using the web page translation function and find that the parameter tk has changed as well as the parameter q (all other parameters have remained the same):
Obviously it is a string dependent token, whose structure is not easy to see, but when you start the web page translation, the following files are loaded:
- 1 CSS file: translateelement.css
- 4 graphics: translate_24dp.png (2x), gen204 (2x)
- 2 JS files: main_de.js , element_main.js
The two JavaScript files are obfuscated and minified. Tools like JS Nice and de4js are now helping us to make these files more readable. In order to debug them live, we recommend the Chrome Extension Requestly, which tunnels remote files locally on the fly:
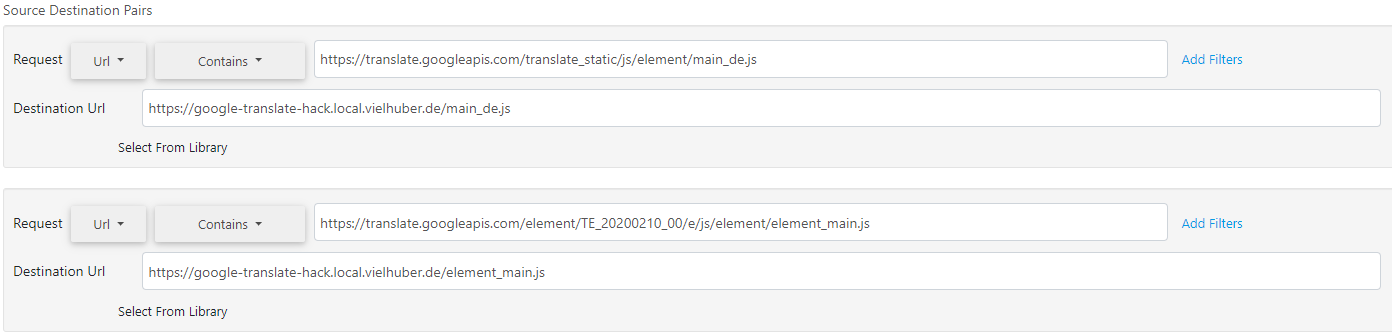
Now we can debug the code ( CORS must be enabled on the local server) The relevant code section for generating the token seems to be hidden in the file element_main.js in this section:
b7739bf50b2edcf636c43a8f8910def9
Here, among other things, the text is hashed with the help of some bit shifts. But unfortunately we are still missing a piece of the puzzle: To the function Bp(), besides the argument a (which is the text to be translated), another argument b is passed - a kind of seed, which seems to change from time to time and which is also included in the hashing. But where does it come from? If we jump to the function call of Bp(), we find the following code section:
b7739bf50b2edcf636c43a8f8910def9
The function Hq is previously declared as follows:
b7739bf50b2edcf636c43a8f8910def9
Here the Deobfuscater left some rubbish; After we have replaced String.fromCharCode ('...') with the respective character strings, remove the obsolete a () and piece together the function calls [c (), c ()] , the result is:
b7739bf50b2edcf636c43a8f8910def9
Or even easier:
b7739bf50b2edcf636c43a8f8910def9
The function yq is previously defined as:
b7739bf50b2edcf636c43a8f8910def9
So the seed seems to be in the global object google.translate._const._ctkk, which is available at runtime. But where is it set? In the other, previously loaded JS-file main_en.js at least it is also available at the beginning. For this we add the following at the beginning:
b7739bf50b2edcf636c43a8f8910def9
In the console we now actually get the current seed:

This leaves Google Chrome itself, which apparently provides the seed, as the last option. Fortunately, its source code (Chromium, including the Translate component) is open source and therefore publicly available. We pull the repository locally and find the call to the TranslateScript :: GetTranslateScriptURL function in the translate_script.cc file in the components / translate / core / browser folder:
b7739bf50b2edcf636c43a8f8910def9
The variable with the URL is hard defined in the same file:
b7739bf50b2edcf636c43a8f8910def9
If we now examine the element.js file more closely (after deobfuscating again), we find the hard-set entry c._ctkk - the google.translate object is also set accordingly and the loading of all relevant assets (which we have already discovered earlier) is triggered:
b7739bf50b2edcf636c43a8f8910def9
Now the parameter key remains for consideration (with the value AIzaSyBOti4mM-6x9WDnZIjIeyEU21OpBXqWBgw). That seems to be a generic browser API key (which can also be found in some Google results ). It is set in Chromium in the file translate_url_util.cc in the folder components / translate / core / browser:
b7739bf50b2edcf636c43a8f8910def9
The key is generated in google_apis / google_api_keys.cc from a dummy value:
b7739bf50b2edcf636c43a8f8910def9
However, a test shows that the API calls work the same without this key parameter. If you experiment with the API, you will get the status code 200 back if you are successful. If you then run into a limit, you get the status code 411 back with the message " POST requests require a content-length header ". It is therefore advisable to include this header (which is automatically set as a temporary header in Postman).
The return format of the translated strings is unusual when there are several sentences in one request, and the individual sentences are enclosed by the i-/b-HTML tags:
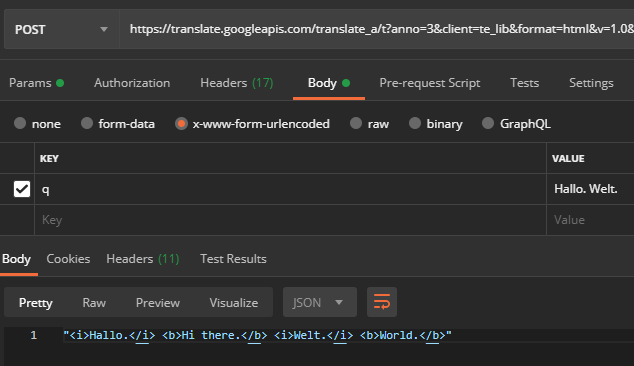
Also, Google Chrome does not send all the HTML to the API, but saves attribute values such as href in the request (and sets indexes instead, so that the tags can be assigned again later on the client side):
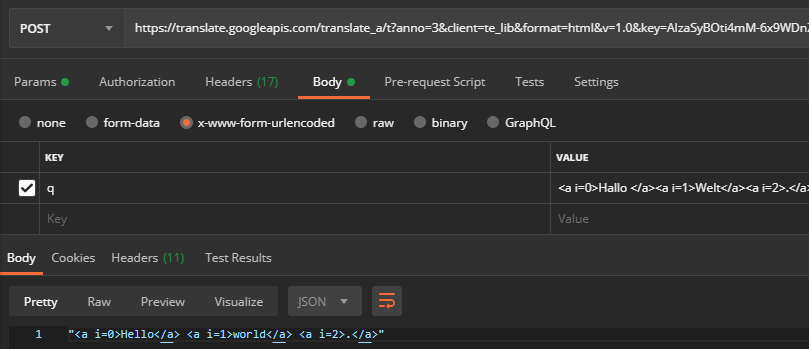
If you change the value of the POST key client from te_lib (Google Chrome) on webapp ( Google Translation website ), you get the final translated string:
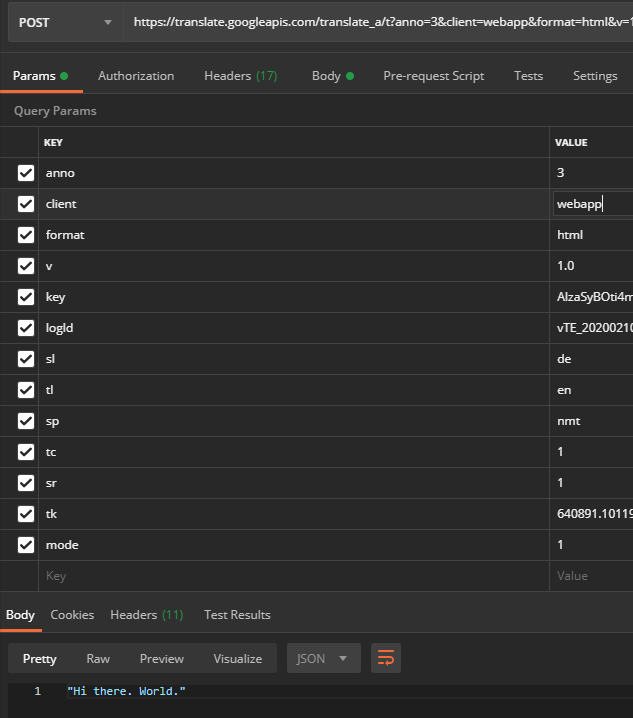
The problem is that you are much more likely to run into rate limiting than via te_lib (for comparison: with webapp this is reached after 40,000 chars, with te_lib there is no rate limiting). So we need to take a closer look at how Chrome parses the result. We'll find it here in element_main.js:
b7739bf50b2edcf636c43a8f8910def9
If you send the entire HTML code to the API, it leaves the attributes in the translated response. We therefore do not have to imitate the entire parse behavior, but only extract the final, translated string from the response. To do this, we build a small HTML tag parser that discards the outermost <i> tags including their content and removes the outermost <b> tags. With this knowledge we can now (after installing dependencies with composer require fzaninotto / faker vielhuber / stringhelper ) build a server-side version of the translation API:
b7739bf50b2edcf636c43a8f8910def9
The following are the results of an initial test that was carried out on five different systems with different bandwidths and IP addresses:
| Character | Characters per request | Duration | Error rate | Cost via official API |
| 13.064.662 | ~250 | 03: 36: 17h | 0% | 237,78€ |
| 24.530.510 | ~250 | 11: 09: 13h | 0% | 446,46€ |
| 49.060.211 | ~250 | 20:39:10h | 0% | 892,90€ |
| 99.074.487 | ~1000 | 61: 24: 37h | 0% | 1803,16€ |
| 99.072.896 | ~1000 | 62:22:20h | 0% | 1803,13€ |
| Σ284.802.766 | ~ Ø550 | Σ159:11:37h | 0% | Σ € 5183.41 |
Note: This blog post, including all scripts, was written for testing purposes only; do not use the scripts for productive use, but work with the official Google Translation API instead.