Googleは、Google Cloudの一部として、使用量ベースのコスト構造を備えたGoogle TranslationAPIを提供しています。 キーなしで使用できるが、ほんの数回の要求の後で機能することを拒否する、文書化されていないAPIもあります。 Google Chromeのウェブサイト翻訳機能を使用すると、目立った制限なしにページを非常に高品質に翻訳できることがわかります。
どうやら、高度なnmtモデルはすでにここで使用されています。 しかし、Google Chromeがコンテンツを翻訳するために内部で使用するAPIはどれですか。また、このAPIは、サーバー側でも直接アドレス指定できますか? ネットワークトラフィックを分析するには、暗号化されたトラフィックも分析できるWiresharkやTelerikFiddlerなどのツールをお勧めします。 ただし、Chromeは、ページの翻訳のために送信するリクエストを無料で配信します。ChromeDevToolsを使用して簡単に表示できます。:
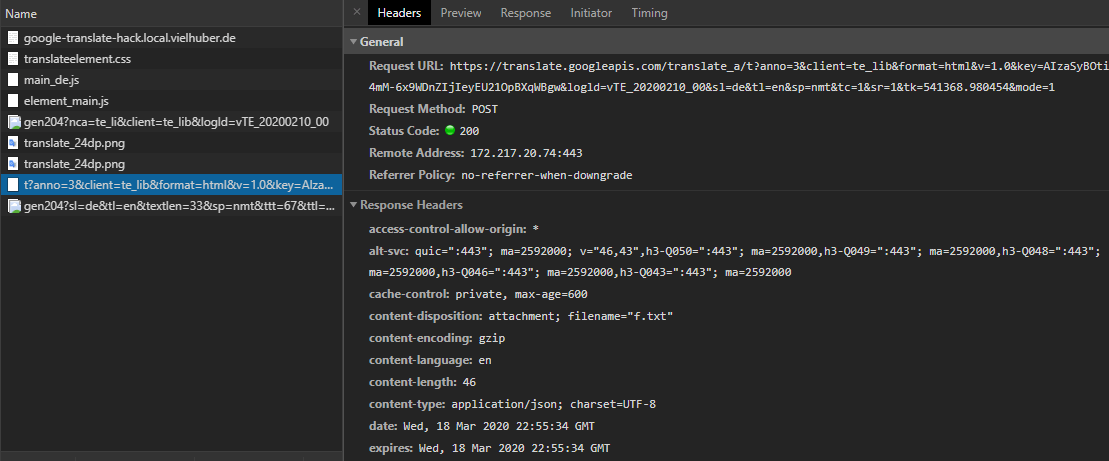
翻訳を実行する場合は、「コピー> cURL(bash)としてコピー」を介してhttps://translate.googleapis.comへの重要なPOSTリクエストをキャッチし、 Postmanなどのツールで実行します。たとえば、問題なくリクエストを再送信できます。:
URLパラメータの意味もおおむね明らかです:
| キー | 値の例 | 意味 |
| 安野 | 3 | 注釈モード(戻り形式に影響します) |
| クライアント | te_lib | クライアント情報(値は異なりますが、Google Translate Webインターフェイスを介した「webapp」です。戻り形式とレート制限に影響します) |
| フォーマット | html | 文字列形式(HTMLタグの翻訳に重要) |
| v | 1.0 | Google翻訳のバージョン番号 |
| キー | AIzaSyBOti4mM-6x9WDnZIjIeyEU21OpBXqWBgw | APIキー(以下を参照) |
| logld | vTE_20200210_00 | プロトコルバージョン |
| sl | de | ソース言語 |
| tl | en | 目標とする言語 |
| sp | nmt | MLモデル |
| tc | 1 | わからない |
| sr | 1 | わからない |
| tk | 709408.812158 | トークン(以下を参照) |
| ファッション | 1 | わからない |
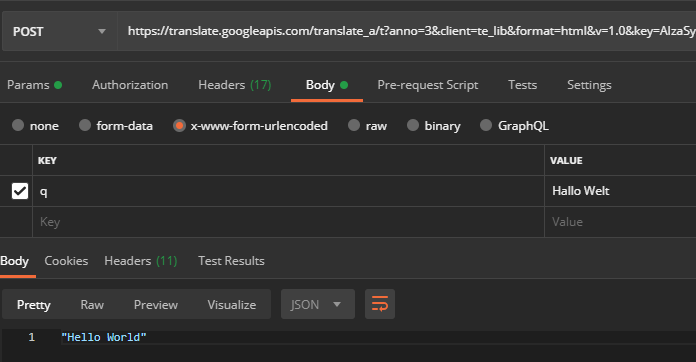
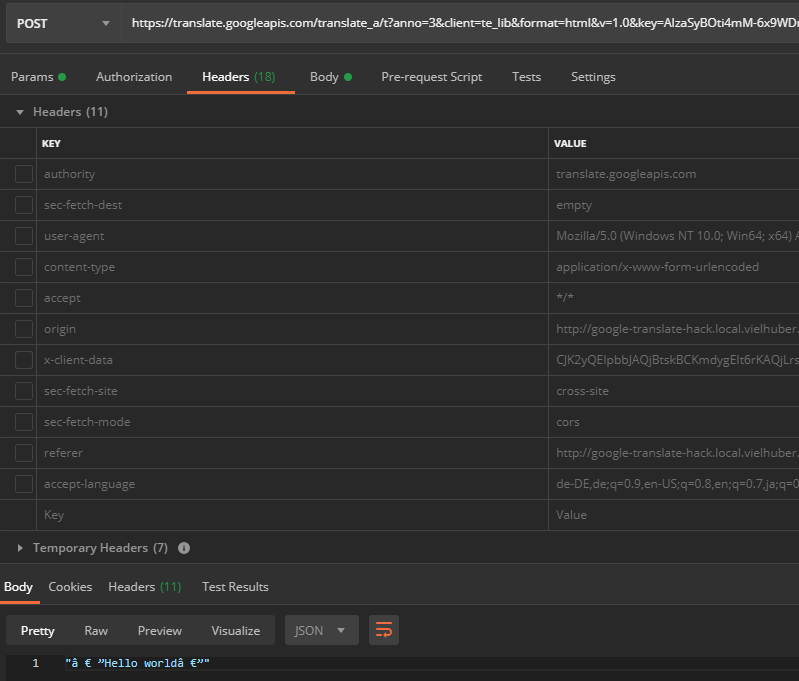
一部のリクエストヘッダーも設定されていますが、これらはほとんど無視できます。 ユーザーエージェントからのヘッダーを含むすべてのヘッダーを手動で選択解除した後、特殊文字を入力するときにエンコードの問題が発見されました(ここでは「 HelloWorld 」を翻訳するとき):
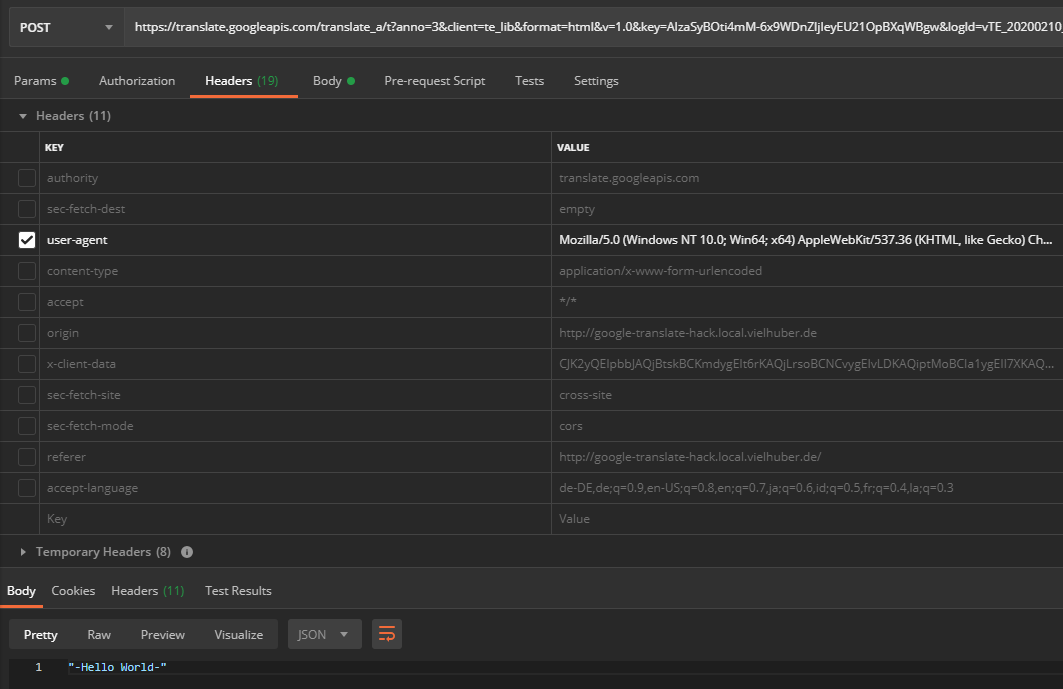
ユーザーエージェントを再アクティブ化すると(通常は害はありません)、APIはUTF-8でエンコードされた文字を配信します:
私たちはすでにそこにいて、Google Chromeの外部でこのAPIを使用するためのすべての情報を持っていますか? たとえば、変換する文字列(POSTリクエストのデータフィールドq )を「Helloworld」から「Helloworld ! 」に変更した場合。 「、エラーメッセージが表示されます:
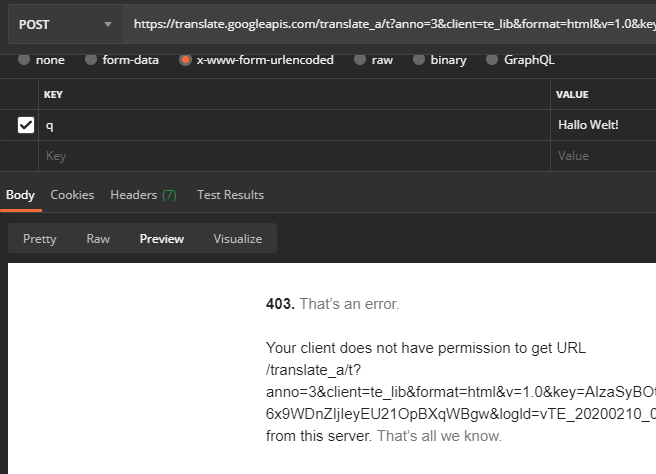
ウェブサイトの翻訳機能を使用して、この変更されたものをGoogle Chrome内で再度翻訳すると、パラメータqに加えて、パラメータtkも変更されていることがわかります(他のすべてのパラメータは同じままです):
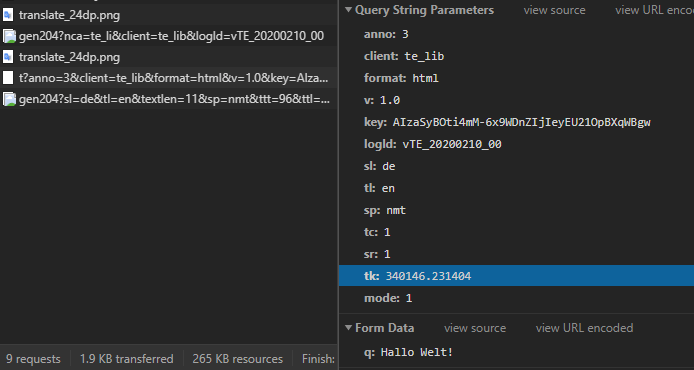
明らかに、それは文字列に依存するトークンであり、その構造は簡単にはわかりません。 ウェブサイトの翻訳を開始すると、次のファイルが読み込まれます:
- 1つのCSSファイル: translateelement.css
- 4つのグラフィック: translate_24dp.png (2x)、 gen204 (2x)
- 2つのJSファイル: main_de.js 、 element_main.js
2つのJavaScriptファイルは難読化され、縮小されています。 JS Niceやde4jsなどのツールは、これらのファイルを読みやすくするのに役立ちます。 それらをライブでデバッグするには、リモートファイルをその場でローカルにトンネリングするChrome ExtensionRequestlyをお勧めします:
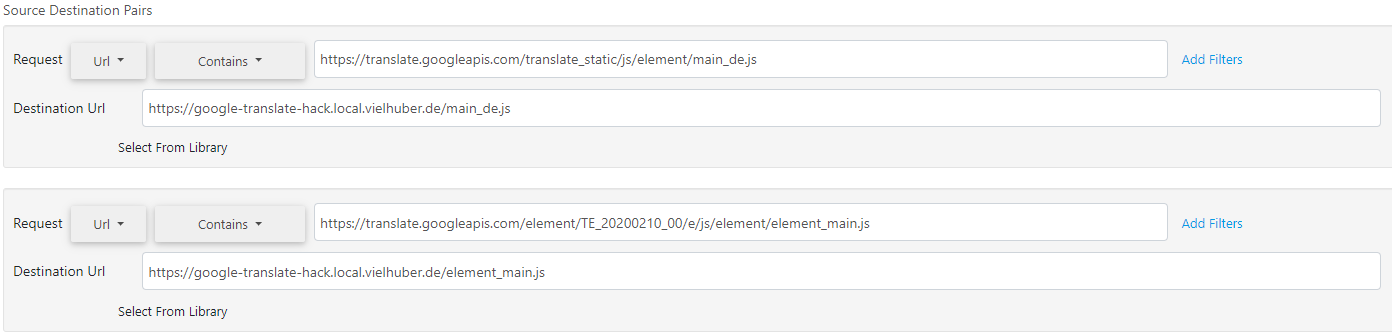
これで、コードをデバッグできます( CORSは最初にローカルサーバーでアクティブ化する必要があります)。 トークンを生成するための関連するコードセクションは、このセクションのelement_main.jsファイルに隠されているようです。:
b7739bf50b2edcf636c43a8f8910def9
ここでは、テキストはいくつかのビットシフトの助けを借りてハッシュされています。 しかし残念ながら、まだパズルの一部が欠けています。引数a (翻訳されるテキスト)に加えて、別の引数bが関数Bp()に渡されます。これは時々変化するように見える一種のシードであり、これには次のものも含まれます。ハッシュに流れ込みます。 しかし、彼はどこから来たのですか? Bp()の関数呼び出しにジャンプすると、次のコードセクションが見つかります。:
b7739bf50b2edcf636c43a8f8910def9
関数Hqは、次のように事前に宣言されています。:
b7739bf50b2edcf636c43a8f8910def9
ここでDeobfuscaterはゴミを残しました。 String.fromCharCode( '...')をそれぞれの文字列に置き換えた後、廃止されたa()を削除し、関数呼び出し[c()、c()]をつなぎ合わせます。結果は次のようになります。:
b7739bf50b2edcf636c43a8f8910def9
またはさらに簡単:
b7739bf50b2edcf636c43a8f8910def9
関数yqは、以前は次のように定義されています。:
b7739bf50b2edcf636c43a8f8910def9
シードは、実行時に使用可能なグローバルオブジェクトgoogle.translate._const._ctkkにあるようです。 しかし、それはどこに設定されていますか? もう1つは、以前にロードされたJSファイルmain_de.jsで、少なくとも最初から利用できます。 最初に以下を追加します:
b7739bf50b2edcf636c43a8f8910def9
コンソールでは、実際に現在のシードを取得します:

これにより、最後のオプションとして、明らかにシードを提供するGoogleChrome自体が残ります。 幸い、そのソースコード(Translateコンポーネントを含むChromium)はオープンソースであるため、公開されています。 リポジトリをローカルにプルし、 components / translate / core / browserフォルダーのtranslate_script.ccファイルでTranslateScript :: GetTranslateScriptURL関数の呼び出しを見つけます。:
b7739bf50b2edcf636c43a8f8910def9
URLを持つ変数は、同じファイルでハード定義されています:
b7739bf50b2edcf636c43a8f8910def9
element.jsファイルをさらに詳しく調べると(再度難読化を解除した後)、ハードセットエントリc._ctkkが見つかります-google.translateオブジェクトもそれに応じて設定され、関連するすべてのアセット(以前に検出済み)のロードがトリガーされます:
b7739bf50b2edcf636c43a8f8910def9
これで、パラメータキーは検討対象のままになります(値AIzaSyBOti4mM-6x9WDnZIjIeyEU21OpBXqWBgwを使用)。 これは一般的なブラウザAPIキーのようです(一部のGoogleの結果にもあります)。 これは、コンポーネント/ translate / core / browserフォルダーのtranslate_url_util.ccファイルのChromiumに設定されています。:
b7739bf50b2edcf636c43a8f8910def9
キーは、ダミー値からgoogle_apis /google_api_keys.ccに生成されます:
b7739bf50b2edcf636c43a8f8910def9
ただし、テストでは、このキーパラメータがなくてもAPI呼び出しが同じように機能することが示されています。 APIを試してみると、成功するとステータスコード200が返されます。 その後、制限に遭遇すると、 「 POST要求にはcontent-lengthヘッダーが必要です」というメッセージとともにステータスコード411が返されます。 したがって、このヘッダー( Postmanで一時ヘッダーとして自動的に設定されます)を含めることをお勧めします。
1つのリクエストに複数の文がある場合、翻訳された文字列の戻り形式は異常です。 個々の文はi- / b-HTMLタグで囲まれています:
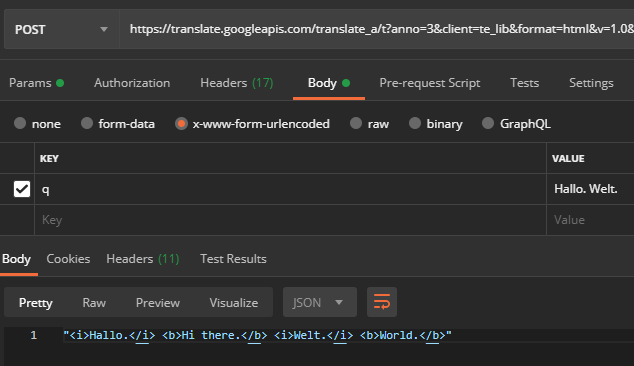
また、Google ChromeはHTML全体をAPIに送信しませんが、リクエストにhrefなどの属性値を保存します(代わりに、タグを後でクライアント側で割り当てることができるようにインデックスを設定します):
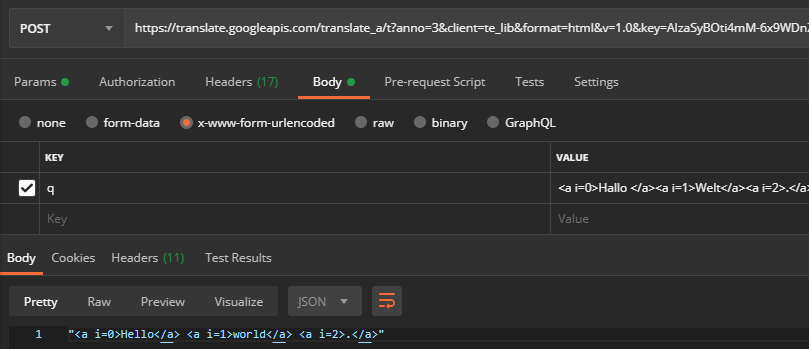
POSTキークライアントの値をte_lib (Google Chrome)から変更した場合 webapp ( Google Translation Webサイト)では、最終的な翻訳文字列を取得します:
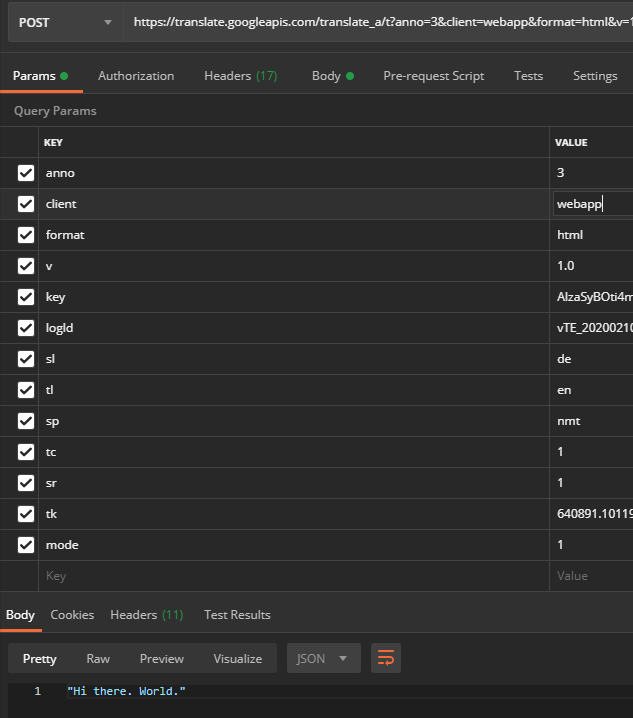
問題は、 te_libを使用するよりもレート制限に遭遇する可能性がはるかに高いことです(比較のために: webappでは40,000文字後に到達しますが、 te_libではレート制限はありません)。 したがって、Chromeが結果をどのように解析するかを詳しく調べる必要があります。 element_main.jsにあります:
b7739bf50b2edcf636c43a8f8910def9
HTMLコード全体をAPIに送信すると、変換された応答に属性が残ります。 したがって、解析動作全体を模倣する必要はありませんが、応答から最終的な変換された文字列を抽出するだけです。 これを行うために、コンテンツを含む最も外側の<i>タグを破棄し、最も外側の<b>タグを削除する小さなHTMLタグパーサーを構築します。 この知識があれば( composerで依存関係をインストールした後、fzaninotto / faker vielhuber / stringhelperが必要です)、サーバー側バージョンの翻訳APIを構築できます。:
b7739bf50b2edcf636c43a8f8910def9
以下は、帯域幅とIPアドレスが異なる5つの異なるシステムで実行された初期テストの結果です。:
| キャラクター | リクエストごとの文字 | 期間 | エラー率 | 公式APIによるコスト |
| 13.064.662 | ~250 | 03:36:17時間 | 0% | 237,78€ |
| 24.530.510 | ~250 | 11:09:13時間 | 0% | 446,46€ |
| 49.060.211 | ~250 | 20:39:10時間 | 0% | 892,90€ |
| 99.074.487 | ~1000 | 61:24:37時間 | 0% | 1803,16€ |
| 99.072.896 | ~1000 | 62:22:20時間 | 0% | 1803,13€ |
| Σ284.802.766 | 〜Ø550 | Σ159:11:37時間 | 0% | Σ€5183.41 |
注:すべてのスクリプトを含むこのブログ投稿は、テスト目的でのみ作成されました。 スクリプトを生産的な使用に使用せず、代わりに公式のGoogle TranslationAPIを使用してください。